Goal-Oriented Research is Its Own Discipline
The most useful thing I’ve learned in two years as a Member of Technical Staff at a research startup is that startup research is not a watered-down version of academic research. It’s a different practice with different rules, and the people who treat it as a compromise of the academic version tend to either burn out or ship nothing.
What the spectrum gets wrong
When people talk about research versus engineering at a startup, they tend to imagine a spectrum with two poles.
Engineering is one pole. There’s a feature that needs to be implemented. There are different ways to implement it, but the end goal is nearly 100% achievable and deterministic. You scope, you build, you ship.
Academic research is the other pole. There are open problems that can be approached through many methods. You rank and prioritize candidate solutions given your hypotheses, and there’s a real chance that none of what you try will work. Great research questions that are well defined shouldn’t have solutions that work the first time around. Otherwise you aren’t being ambitious enough. Research requires iteration. Exploration is a forcing function in this environment that gives you more priors to make a decision on the next experiment to try.
The standard story is that startup research lives somewhere between these two poles. You take an academic problem and give it a deadline. You take an engineering practice and loosen the success criteria. What you get is a compromise that pleases neither the researcher nor the engineer but ships occasionally.
I don’t think this is what successful startup research actually looks like. The compromise framing assumes you’re trading off on the same axis. You aren’t.
The actual structure
When you’re doing goal-oriented research at a startup, you have to pick a point along the pareto that trades off exploration (research) versus exploitation (engineering). This trade-off doesn’t get made once at the project level. It gets made continuously, at every level, against a target that keeps moving.
The sparse final reward of binary success criteria in research cannot be equated as is to the milestone structure of engineering. Achieving an x% gain on an eval is not the same kind of milestone as shipping a customer feature request in the UI. The eval gain might require a methodological pivot and weeks of staring at model outputs. The feature request requires a sprint plan and someone who knows React. Treating these as interchangeable items on the same backlog is how startups end up either shipping nothing or doing fake research that’s actually engineering with a fancier label.
The framing trick
So how do you plan research that has to ship?
The framing I’ve landed on is this. The high level goal, the final deliverable, should be framed as the long-term research vision. Not because the goal is open-ended in the academic sense, but because the path to it is uncertain. The path might require several pivots. The success criterion is real but distant.
The next immediate problem to tackle, the thing your team is actually doing this sprint, should be framed as an engineering problem. Here is the well-defined problem with supporting evidence and diagnosis so far. Here’s the specific time span we’re going to dedicate to throwing all possible human labor and compute and ranked candidate solutions at it. Once we run into the next problem, then we have collected more information about what failed or maybe worked, and we do the next round of planning. The current step is treated as a feature request along the way of the long-term research vision.
Schematically:
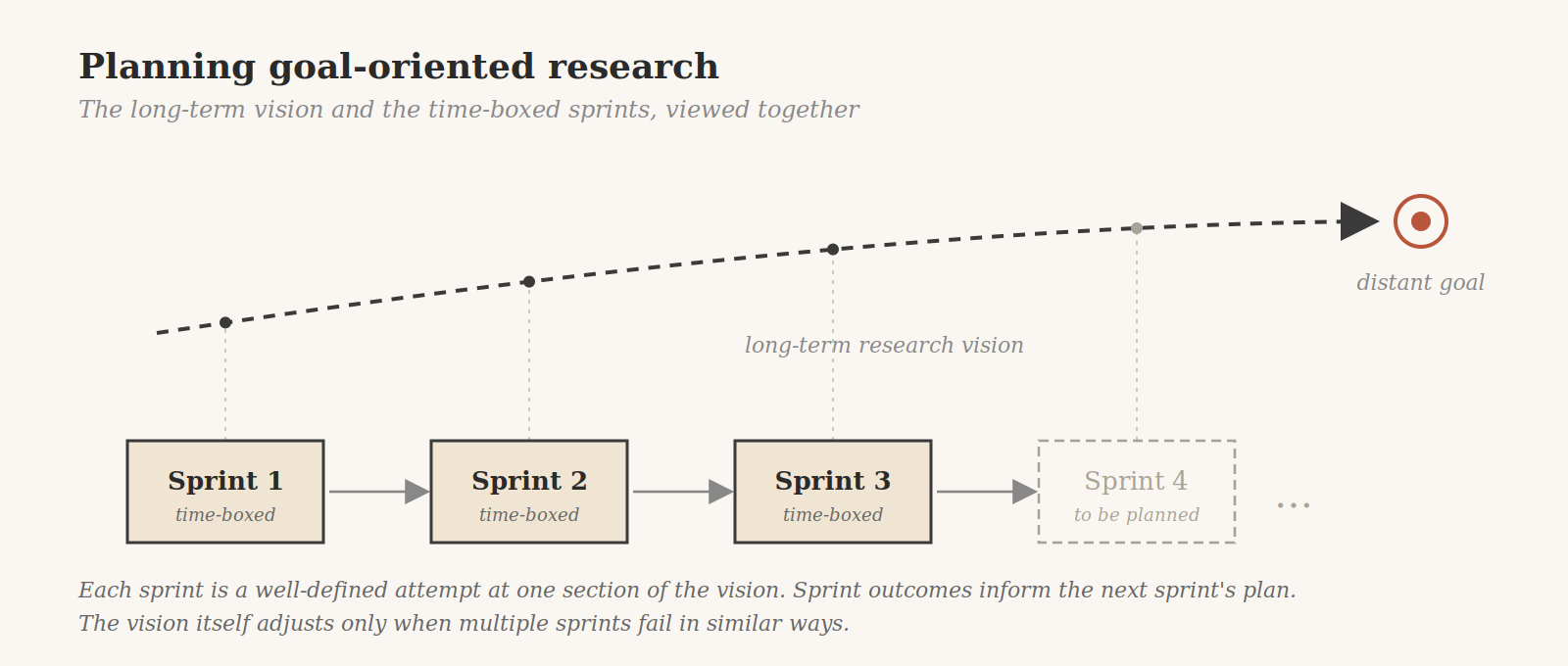
This sounds like a semantic trick. I don’t think it is. The reframing changes how you actually run the work.
It changes how you allocate. The long-term research vision gets resourced like a research bet: you commit budget against an uncertain payoff. The current sprint gets resourced like an engineering project: you commit specific people for a specific time, and you measure them against whether the well-defined sub-problem got solved.
It also changes how you communicate. To customers and executives, the long-term vision is the story. To the team executing this week, the story is the time-boxed engineering problem. Trying to communicate the vision as a sprint goal makes the team feel like they’re failing constantly. Trying to communicate the sprint goal as the vision makes the customer think you have no ambition. The two registers are not interchangeable, and confusing them is a common failure mode.
Most importantly, it changes how you decide when to pivot. If the sprint engineering problem fails, that’s information. You re-plan the next sprint with the new information. The long-term vision doesn’t change just because one sprint failed. But if multiple sprints in a row fail in similar ways, that’s a signal that the vision itself needs adjustment. The two timescales let you separate noise from signal.
What this requires
This framing only works if the leadership tier holds both timescales simultaneously. If your CTO only cares about the engineering sprint, the research vision evaporates and you become a feature factory. If your chief scientist only cares about the research vision, the engineering sprints lose discipline and nothing ships. The two have to be in active conversation, and the people doing the work have to translate between the two registers fluently.
This is, I suspect, why the most senior people at research startups tend to be those who can hold both framings at once. Not because they’re equally good at every individual skill in the engineering-research simplex, but because they can make decisions that respect both timescales without collapsing one into the other. The rest of us are still learning how to do this.
If you’re running a research startup, the sooner you stop planning for one timescale and start planning for two, the sooner you stop burning out the researchers on your team.